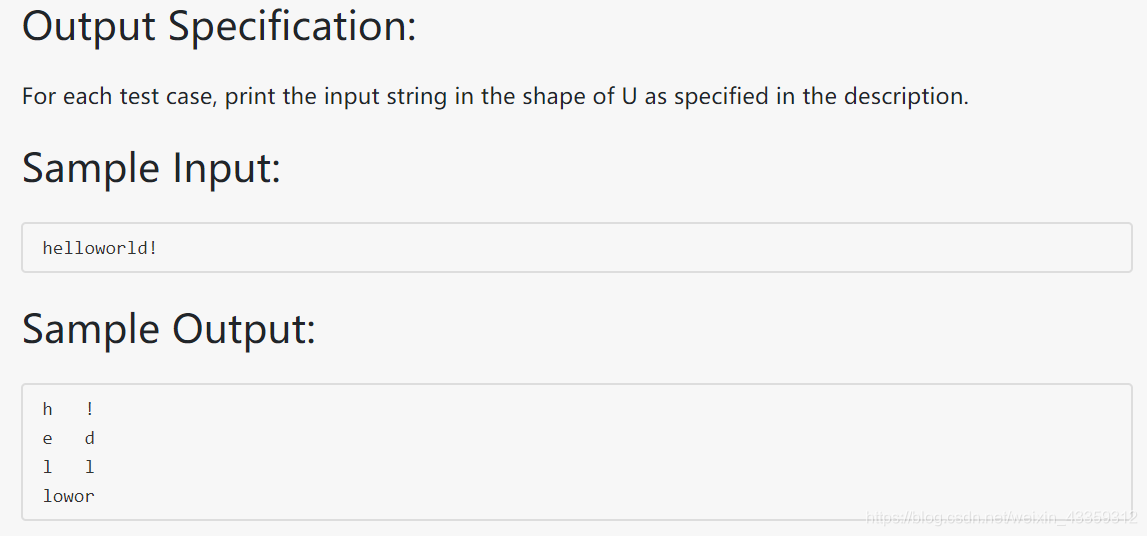
1031 Hello World for U (20 分)
本文共 2103 字,大约阅读时间需要 7 分钟。
1031 Hello World for U (20 分)

常规代码
#include#include using namespace std;int main() { string S; cin >> S; int Len = S.size(); int VLen = (Len + 1) / 3; char U[40][40]; for (int i = 0; i < 40; i++) for (int j = 0; j < 40; j++) U[i][j] = ' '; int i = 0; if ((Len + 1) % 3 == 0) { for (int row = 0; row < VLen; row++) { if (row == VLen - 1) { for (int k = 0; k <= VLen; k++) U[row][k] = S[i++]; } else U[row][0] = S[i++]; } for (int row = VLen - 2; row >= 0; row--) U[row][VLen] = S[i++]; int p, q; for (p = 0; p < VLen; p++) { for (q = 0; q <= VLen; q++) { if (q == VLen) cout << U[p][q] << endl; else cout << U[p][q]; } } } else if ((Len + 1) % 3 == 1) { for (int row = 0; row < VLen; row++) { if (row == VLen - 1) for (int k = 0; k <= VLen + 1; k++) U[row][k] = S[i++]; else U[row][0] = S[i++]; } for (int row = VLen - 2; row >= 0; row--) U[row][VLen + 1] = S[i++]; int p, q; for (p = 0; p < VLen; p++) { for (q = 0; q <= VLen + 1; q++) { if (q == VLen + 1) cout << U[p][q] << endl; else cout << U[p][q]; } } } else if ((Len + 1) % 3 == 2) { for (int row = 0; row <= VLen; row++) { if (row == VLen) for (int k = 0; k <= VLen; k++) U[row][k] = S[i++]; else U[row][0] = S[i++]; } for (int row = VLen - 1; row >= 0; row--) U[row][VLen] = S[i++]; int p, q; for (p = 0; p <= VLen; p++) { for (q = 0; q <= VLen; q++) { if (q == VLen) cout << U[p][q] << endl; else cout << U[p][q]; } } } return 0;}
优化代码
#include#include #include using namespace std;int main() { char S[100]; scanf("%s", S); int Len = strlen(S); int n1 = (Len + 2) / 3, n3 = n1, n2 = Len + 2 - n1 * 2; char U[40][40]; for (int i = 1; i <= n1; i++) for (int j = 1; j <= n2; j++) U[i][j] = ' '; int pos = 0; for (int i = 1; i <= n1; i++) U[i][1] = S[pos++]; for (int j = 2; j <= n2; j++) U[n1][j] = S[pos++]; for (int k = n3 - 1; k > 0; k--) U[k][n2] = S[pos++]; for (int i = 1; i <= n1; i++) { for (int j = 1; j <= n2; j++) cout << U[i][j]; cout << endl; } return 0;}
转载地址:http://jlipz.baihongyu.com/
你可能感兴趣的文章
memset初始化高维数组为-1/0
查看>>
Metasploit CGI网关接口渗透测试实战
查看>>
Metasploit Web服务器渗透测试实战
查看>>
MFC模态对话框和非模态对话框
查看>>
Moment.js常见用法总结
查看>>
MongoDB出现Error parsing command line: unrecognised option ‘--fork‘ 的解决方法
查看>>
mxGraph改变图形大小重置overlay位置
查看>>
MongoDB可视化客户端管理工具之NoSQLbooster4mongo
查看>>
Mongodb学习总结(1)——常用NoSql数据库比较
查看>>
MongoDB学习笔记(8)--索引及优化索引
查看>>
mongodb定时备份数据库
查看>>
mppt算法详解-ChatGPT4o作答
查看>>
mpvue的使用(一)必要的开发环境
查看>>
MQ 重复消费如何解决?
查看>>
mqtt broker服务端
查看>>
MQTT 保留消息
查看>>
MQTT 持久会话与 Clean Session 详解
查看>>
MQTT介绍及与其他协议的比较
查看>>
MQTT工作笔记0007---剩余长度
查看>>
MQTT工作笔记0008---服务质量
查看>>